This sample application demonstrates the use of a Pravega abstraction, the StreamCut, in a Flink application to make
it easier for developers to write analytics applications.
Purpose
The objective of this sample is to demonstrate that:
1. Flink applications may use StreamCut to bookmark points of interest within a Pravega Stream
2. StreamCut can be stored as persistent bookmarks for a Pravega stream
3. StreamCut may be used to perform bounded stream/batch processing on slices bookmarked by a Flink application.
Note: The Dell EMC Streaming Data PlatformSince has the full Flink runtime which includes a JobManager and a TaskManager. However, this sample uses the local Flink environment which is designed to run a program within a local JVM. Thus, the instruction for Dell EMC Streaming Data Platform setup will be just using remote Pravega cluster instead of deploying the application to SDP. However, it could be an academic exercise to enhance the example and run on Dell EMC SDP.
Design
The example consists of three applications: DataProducer, StreamBookmarker and SliceProcessor.
$ cd flink-connector-examples/build/install/pravega-flink-examples
$ bin/dataProducer [--controller tcp://localhost:9090] [--num-events 10000]
$ bin/streamBookmarker [--controller tcp://localhost:9090]
$ bin/sliceProcessor [--controller tcp://localhost:9090]
First, let us describe the role that these applications play in the sample:
-
DataProducer: This application is intended to create data simulating various sensors publishing events. Each event is a tuple<sensorId, eventValue>. In particular, the values of events follow a sinusoidal function to have intuitive changing values within a controlled range for a demonstration. -
StreamBookmarker: This Flink application is intended to identify the slices of theStreamthat we want to bookmark, as they are of interest to execute further processing. That is, for a givensensorId, this job detects and stores the start and endStreamCut(i.e.,Stream“slice”) for whicheventValuesare< 0. With the start and endStreamCut, this application creates a “slice” object that is persistently stored in a separate PravegaStream. -
SliceProcessor: This application reads from the PravegaStreamwhere the start and endStreamCutare published byStreamBookmarker. For each stream slice object written in theStream, this application executes (locally) a batch job that reads the events within the specified slice and performs some computation (e.g., counting events for the sensor for which values are< 0). This is an example of bounded processing in Flink on a PravegaStream.
Instructions
A. Running example on a local cluster with support from Pravega
1. Setting up the Pravega and Flink environment
Before you start, you need to download the latest Pravega release on the github releases page. See here for the instructions to build and run Pravega in standalone mode.
Besides, you also need to get the latest Flink binary from Apache download page. Follow this tutorial to start a local Flink cluster.
2. Build pravega-samples Repository
pravega-samples repository provides code samples to connect analytics engines Flink with Pravega as a storage substrate for data streams. It has divided into sub-projects(pravega-client-examples, flink-connector-examples and hadoop-connector-examples), each one addressed to demonstrate a specific component. To build pravega-samples from source, follow the instructions to use the built-in gradle wrapper.
3. Start the Streamcuts Flink Example program
There are multiple ways to run the program in Flink environment including submitting from terminal or Flink UI. Follow the latest instruction from the github README to learn more about the IDE setup and running process.
B. Running example on Dell EMC Streaming Data Platform
1. Change the Streamcuts example code to satisfy the SDP running requirements
Since the original flink connector Streamcuts Flink example was designed to run on a standalone Pravega and Flink environment, the code used the createScope method from the StreamManager Interface in Pravega. However, due to the security reason, Dell EMC Streaming Data Platform does not allow to create a scope from the code. Please comment out createScope method from your code.
There are three occurrences of createScope method in this Streamcuts Flink example which locate on following Java file:
I. pravega-samples/flink-connector-examples/src/main/java/io/pravega/example/flink/streamcuts/process/DataProducer.java
II. pravega-samples/flink-connector-examples/src/main/java/io/pravega/example/flink/streamcuts/process/StreamBookmarker.java
III. pravega-samples/flink-connector-examples/src/main/java/io/pravega/example/flink/streamcuts/process/SliceProcessor.java
2. Follow the this post to learn how to create Flink projects and run on Dell EMC Streaming Data Platform
The post for Create Flink Project On Streaming Data Platform was designed for the Flink application running on Dell EMC Streaming Data Platform. Since this code sample only needs the Pravega cluster from the Dell EMC Streaming Data Platform, you can skip Step C: Create Flink Clusters through Step F. Check Project Status in the post.
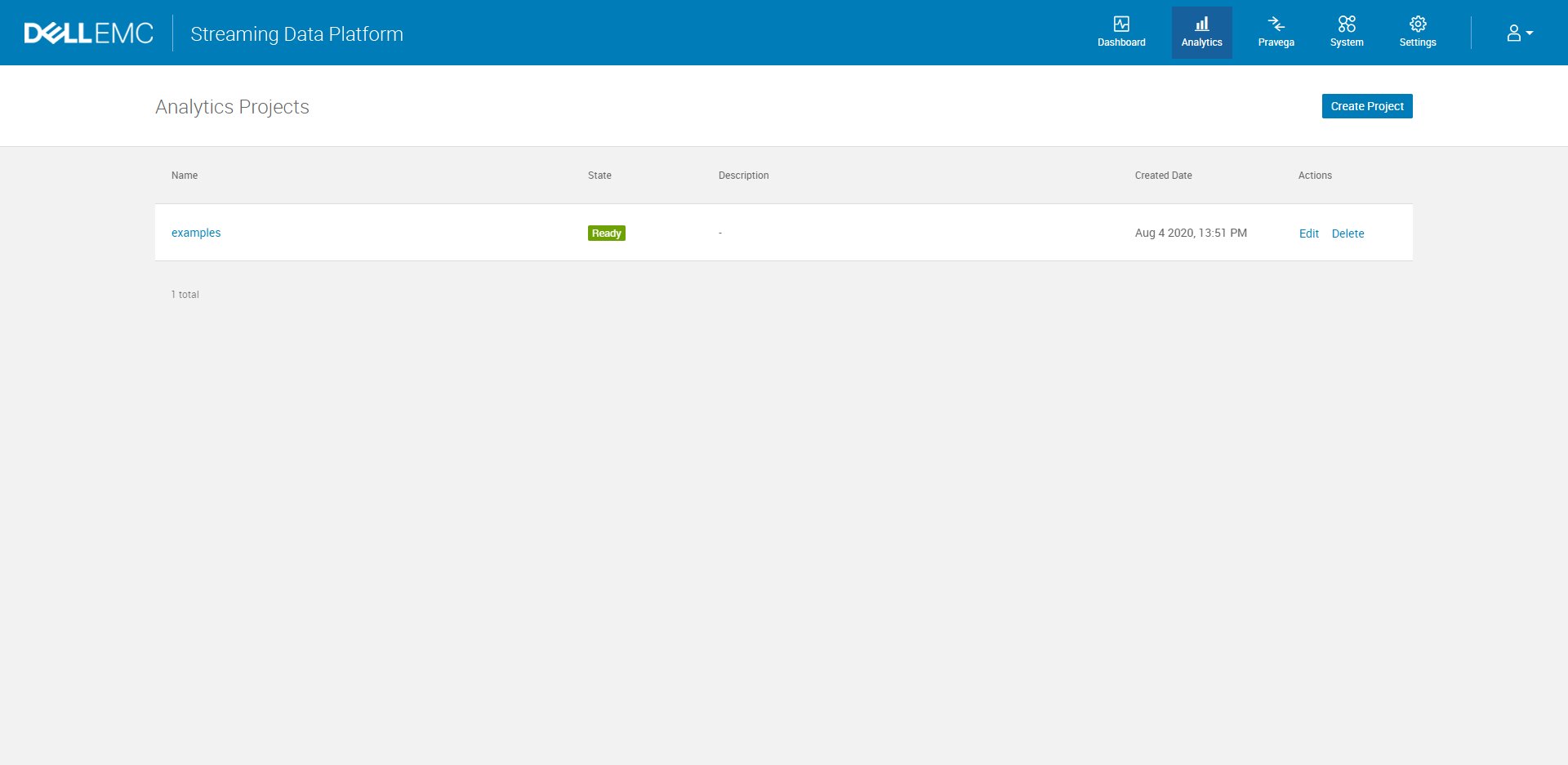
In addition, since the code sample uses the default scope name, the name/namespace for this project must be examples. You should have the same Analytics Projects Dashboard as follows:
3. Connect the DataProducer, StreamBookmarker, and SliceProcessor application with the Pravega stream on Dell EMC Streaming Data Platform
After setting up the project namespace on SDP, configure Keycloak authentication by following this post. You need to set the same configurations for the DataProducer, StreamBookmarker, and SliceProcessor application. Then you can run the applications with the same order as discussed in the original post.
4. Check the result after running Streamcuts Flink example
The result will be showing in your terminal or the console if you are using IntelliJ. You will find the same results as shown in the github README.
Source
https://github.com/pravega/pravega-samples/tree/master/flink-connector-examples/doc/streamcuts
